データエクスポート
データエクスポートの紹介¶
これは、Hive Analyticsから毎時ログデータを抽出し、クラウドストレージに転送するサービスです。
データエクスポートによって生成されたデータは、必要に応じて分析に使用できます。生データとして直接データベースを構築するか、必要な形式に処理することができます。
Hive Analyticsはファイル変換とデータ転送を提供していますが、クラウドストレージには利用しているクラウドプロバイダーへの登録が必要です。
データエクスポートロジック¶
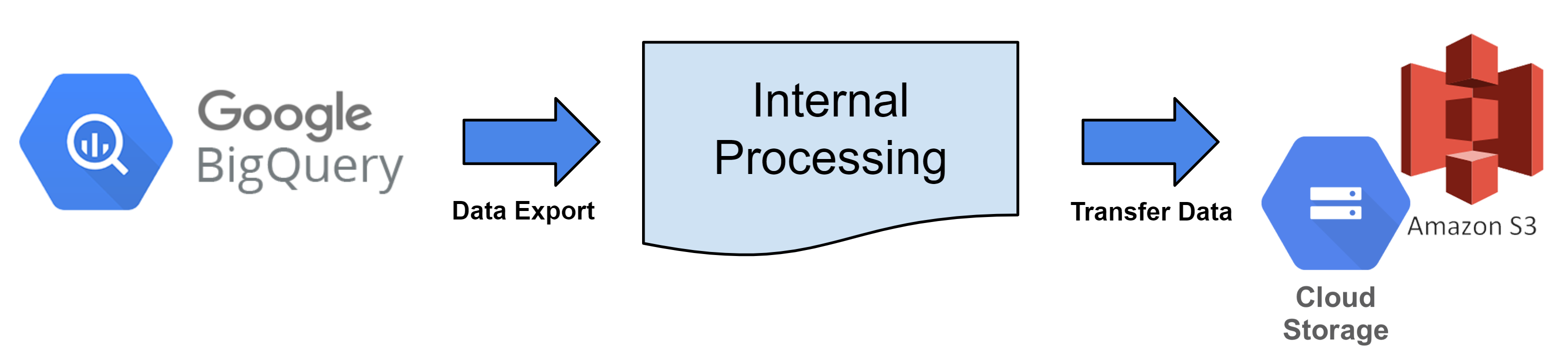
毎時、BigQueryテーブルはデータエクスポートサイクルに従ってファイルに変換され、登録されたクラウドストレージにアップロードされます。
データエクスポートサービスの権限¶
- データエクスポート機能を使用するには、すべてのゲームにアクセスするか、Hiveアカウントを所有している必要があります。
- データはテーブル(ログ)によって配信されるため、ゲームごとの分割送信は不可能です。
データエクスポートデータ基準¶
- 選択したテーブルデータを検索し、ファイルをクラウドストレージにアップロードします。
- データはUTCに基づく1時間ごとの送信サイクルを使用して抽出されます。 E.g.) 2023年9月1日 00:00:00 - 00:59:59 (UTC) のデータを2023年9月1日 1:00 (UTC) に抽出します。
- 日時列のパーティショニング基準は、ビュー日から1日前に設定されています。 E.g.) 2023年9月1日 00:00:00から00:59:59 (UTC) のデータを抽出する場合、2023年8月30日 00:00:00です。
- 日時の値がクエリ時間から1日前よりも小さい場合、エクスポートデータから除外されます。
- 日時列のパーティショニング基準は、ビュー日から1日前に設定されています。 E.g.) 2023年9月1日 00:00:00から00:59:59 (UTC) のデータを抽出する場合、2023年8月30日 00:00:00です。
- データはBig Queryに入力された時間に従って検索されます。
- bigqueryRegistTimestamp列の基準
- データ抽出サンプルクエリ
SELECT *
FROM bigquery_table
WHERE bigqueryRegistTimestamp BETWEEN '2023-09-01 00:00:00' and '2023-09-01 00:59:59'
and datetime >= '2023-08-31 00:00:00'
データエクスポート設定¶
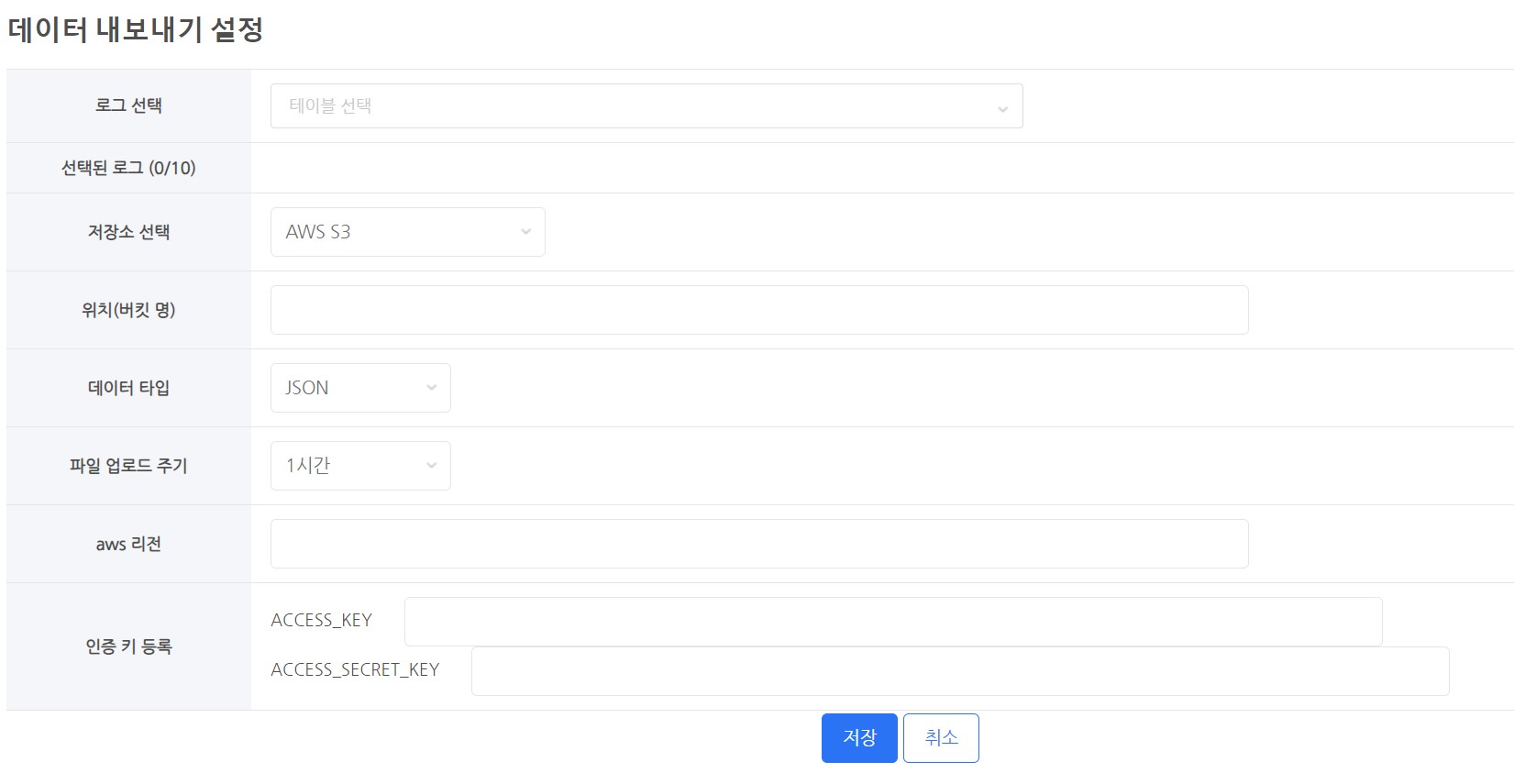
ログを選択¶
- 抽出するテーブル(ログ)を選択します。
- テーブル名の一部を入力することで検索して選択できます。
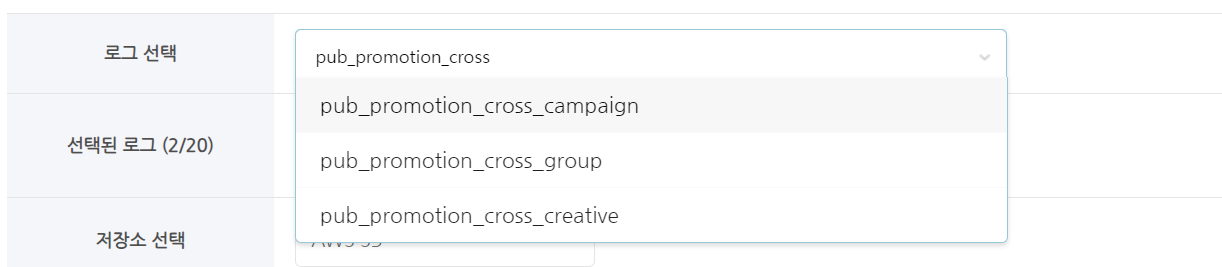
- 最大で10個のテーブルを選択できます。

- テーブル名の一部を入力することで検索して選択できます。
ストレージを選択¶
- データを保存するためにクラウドストレージを使用する必要があります。
- サポートされているクラウド
- AWS S3
- GCP Google Cloud Storage
場所 (バケット名)¶
- ストレージのバケット名を入力してください。
- 例:)
- AWS S3バケット名がs3://s3_bucket_nameの場合、
- 「s3_bucket_name」のみを入力してください。
- Google Cloud Storageバケット名がgs://google_bucket_nameの場合、
- 「google_bucket_name」のみを入力してください。
- AWS S3バケット名がs3://s3_bucket_nameの場合、
データ型¶
- データ型は2つあります。
- 提供されるデータ型
- CSV
- JSON
- すべてのファイルはUTF-8でエンコードされています。
ファイルアップロードサイクル¶
- 毎時範囲からデータが抽出され、毎時アップロードされます。
- 抽出のための時間はbigqueryRegistTimestamp列の値に基づいています。(UTCに基づく)
- 例)15:00(UTC)にデータの抽出とアップロードを開始します。
- bigqueryRegistTimestamp列には05:00:00から05:59:59までのデータがあります。
- 完了時間はファイルの数とアップロードサイズによって異なる場合があります。
- 例)15:00(UTC)にデータの抽出とアップロードを開始します。
認証キーを登録する¶
- データをクラウドストレージにアップロードするには、許可が必要です。
- データストレージの権限を持つ認証キーまたは認証キーファイルを登録する必要があります。
- 認証キーの登録技術はクラウドサービスによって異なります。

- S3 - ACCESS_KEY、ACCESS_SECRET_KEY 認証値を登録

- GCS - 認証キーファイルを登録
クラウドストレージ¶
GCP - Google Cloud Storage¶
- データをGoogle Cloudにエクスポートするには、以下の設定が必要です。
-
- Google Cloud Consoleページに移動し、Cloud Storageを選択します。

- データエクスポート専用のバケットを作成します。
- 一度設定すると、バケット名は変更できません。必要な場合は、古いバケットを削除して新しいバケットを作成してください。
- データエクスポート専用のバケットを作成することをお勧めします。
- データエクスポートを有効にするには、サービスキーを作成し、バケットに書き込み権限を付与します。
- コンソールページからIAM & Admin → サービスアカウントを選択します。
- 新しいアカウントを設定するには、サービスアカウントを作成をクリックします。
- アカウントに希望の名前に一致するIDを付けることができます。
- 例) hive_data_transfer_account@projectId.iam.gserviceaccount.com
- アカウントを作成した後、キーのタブに移動し、サービスのキーを生成します。

- キーの追加 → 新しいキーを作成からJSON形式のキーを作成します。
- 作成したキーのファイルをダウンロードした後、安全に保管してください。
- アカウントに希望の名前に一致するIDを付けることができます。
- 次に、Cloud Storageに戻り、作成したバケットの権限タブに移動します。

- 権限タブで、新しく作成したサービスアカウントIDを「アクセスを付与」→「主要メンバーを追加」に入力します。
- 役割の割り当てで、2つの権限を確認します: Cloud Storage → ストレージオブジェクト作成者およびストレージオブジェクトビューワー、その後「OK」をクリックします。
- すべての設定が完了したら、Hive Analyticsのデータエクスポート設定ページに移動し、サービスのキーのファイルを登録します。
- Google Cloud Consoleページに移動し、Cloud Storageを選択します。
AWS - S3¶
- AWSにデータをエクスポートするには、以下の設定が必要です。
-
- AWSコンソールでストレージ → S3に移動します。

- データエクスポート用のバケットを作成します。
- 設定後、バケット名は変更できません。必要な場合は、古いバケットを削除して新しいものを作成してください。
- データエクスポート専用のバケットを作成することをお勧めします。
- データエクスポート用のバケットを作成します。
- このユーザーはデータエクスポート専用のスタンドアロンアカウントとしてのみ使用するべきです。新しいIAMユーザーを作成します。
- 作成したアカウントのアクセスキーを作成します。関連情報はIAMユーザーのアクセスキー管理 - アクセスキーの作成で確認できます。
- アクセスキーは安全な場所に保管してください。
- 作成したアカウントにインラインポリシーを追加します。
- ユーザーグループ(コンソール)にインラインポリシーを含めるには、ポリシー作成のトピックに従って手順を進めます。
-
ポリシーを設定するには、JSONタブを選択し、以下に示すJSONコードを貼り付けます。
- YOUR-BUCKET-NAME-HEREフィールドには、あなたが設定したバケットの名前が含まれています。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": ["s3:GetBucketLocation", "s3:ListBucket"], "Resource": ["arn:aws:s3:::YOUR-BUCKET-NAME-HERE"] }, { "Effect": "Allow", "Action": ["s3:PutObject"], "Resource": ["arn:aws:s3:::YOUR-BUCKET-NAME-HERE/*"] } ] }
- YOUR-BUCKET-NAME-HEREフィールドには、あなたが設定したバケットの名前が含まれています。
- すべてが完了したら、アーカイブされたアクセスキーをHiveコンソールのデータエクスポートオプションに追加します。
- AWSコンソールでストレージ → S3に移動します。
ファイルストレージフォーマット¶
データストレージディレクトリ構造¶
- 一般的なファイル形式
- withhive/data_export/Build_Type/YYYY/MM/DD/TableName/TableName_YYYY_MM_DD_UUID.fileExtension
- ビルドタイプ: サンドボックスとライブの2つの可能な値があります。サンドボックスに設定すると、サンドボックスとして保存されます。
- YYYY/MM/DD : データが抽出される標準の年/月/日です。(UTCに基づく)
- UUID : 重複ファイル名による上書きを防ぐためのランダムな値です。
-
ファイル拡張子: 選択したファイルタイプに基づいて異なります。
- withhive/data_export/Build_Type/YYYY/MM/DD/TableName/TableName_YYYY_MM_DD_UUID.fileExtension
| ファイルタイプ | 圧縮状況 | 最終ファイル名 |
|---|---|---|
| json | V | withhive/data_export/BuildType/YYYY/MM/DD/TableName/TableName_YYYY_MM_DD_UUID.json.gzip |
| csv | V | withhive/data_export/BuildType/YYYY/MM/DD/TableName/TableName_YYYY_MM_DD_UUID.csv.gzip |
ファイル拡張子¶
- csv.gzip
- これは、フィールドがカンマで区切られたデータを含むファイルです。
- ファイルを圧縮する際に暗号化設定は使用できません。(サポートされていません)
- json.gzip
- これは、Javascriptオブジェクト構文で整理されたデータ文字を含むファイルです。
- 行に分かれています。
- gzipで圧縮されたjsonファイルです。
- ファイルを圧縮する際に暗号化設定は使用できません。(サポートされていません)
送信制限通知¶
- 最大テーブル数制限
- 選択可能なテーブルの最大数: 10
- テーブルごとのデータ抽出総容量制限
- データを抽出する際に500Mbytesを超える場合: 転送から除外
- 実際に転送されるデータは約15%の圧縮ファイルです。
- データを抽出する際に500Mbytesを超える場合: 転送から除外