데이터 내보내기
데이터 내보내기 소개¶
하이브 애널리틱스로 적재 중인 로그 데이터를 매시간 추출하여 클라우드 저장소로 업로드하는 서비스 입니다.
데이터 내보내기에서 제공되는 데이터는 로우(raw) 데이터로 직접 데이터 베이스를 구축하거나 원하는 형태로 가공하여 목적에 따라 분석에 사용할 수 있도록 제공해 드립니다.
데이터의 파일 변환과 전송은 하이브 애널리틱에서 제공해드리고 있으나 클라우드 스토리지는 사용하시는 클라우드의 서비스로 등록을 하셔야 합니다.
데이터 내보내기 로직¶

빅쿼리에 저장되어있는 테이블을 매시간 데이터 내보내기 주기에 맞춰 파일로 변환하여
등록한 클라우드 스토리지로 업로드 됩니다.
데이터 내보내기 서비스 사용 권한¶
- 데이터 내보내기 서비스를 사용하기 위해서는 모든 게임에 대한 권한을 보유하거나 하이브 계정 오너(owner)인 경우에만 가능합니다.
- 테이블(로그)별 데이터 제공으로 게임별 분할 전송은 되지 않습니다.
데이터 내보내기 데이터 기준¶
- 선택한 테이블 데이터를 조회하여 클라우드 저장소로 파일 전송을 합니다.
- 데이터는 UTC를 기준으로 매시간 전송 주기에 따라 추출합니다. 예) 2023년 9월 1일 01:00 (UTC)에 2023년 9월 1일 00:00:00 ~ 00:59:59 (UTC)의 데이터를 기준으로 추출하여 전송
- 파티셔닝 기준은 datetime컬럼에 대해서 조회일 -1 day로 설정됩니다. 예) 2023년 9월 1일 00:00:00 ~ 00:59:59(UTC)의 데이터를 기준으로 추출 시 2023년 8월 30일 00:00:00
- datetime의 값이 조회시간 -1 day보다 더 작은 경우 내보내기 데이터에 포함되지 않습니다.
- 파티셔닝 기준은 datetime컬럼에 대해서 조회일 -1 day로 설정됩니다. 예) 2023년 9월 1일 00:00:00 ~ 00:59:59(UTC)의 데이터를 기준으로 추출 시 2023년 8월 30일 00:00:00
- 데이터는 빅쿼리에 데이터가 입력된 시간으로 조회를 합니다.
- bigqueryRegistTimestamp 컬럼 기준
- 데이터 추출 sample Query
SELECT *
FROM bigquery_table
WHERE bigqueryRegistTimestamp BETWEEN '2023-09-01 00:00:00' and '2023-09-01 00:59:59'
and datetime >= '2023-08-31 00:00:00'
데이터 내보내기 설정¶
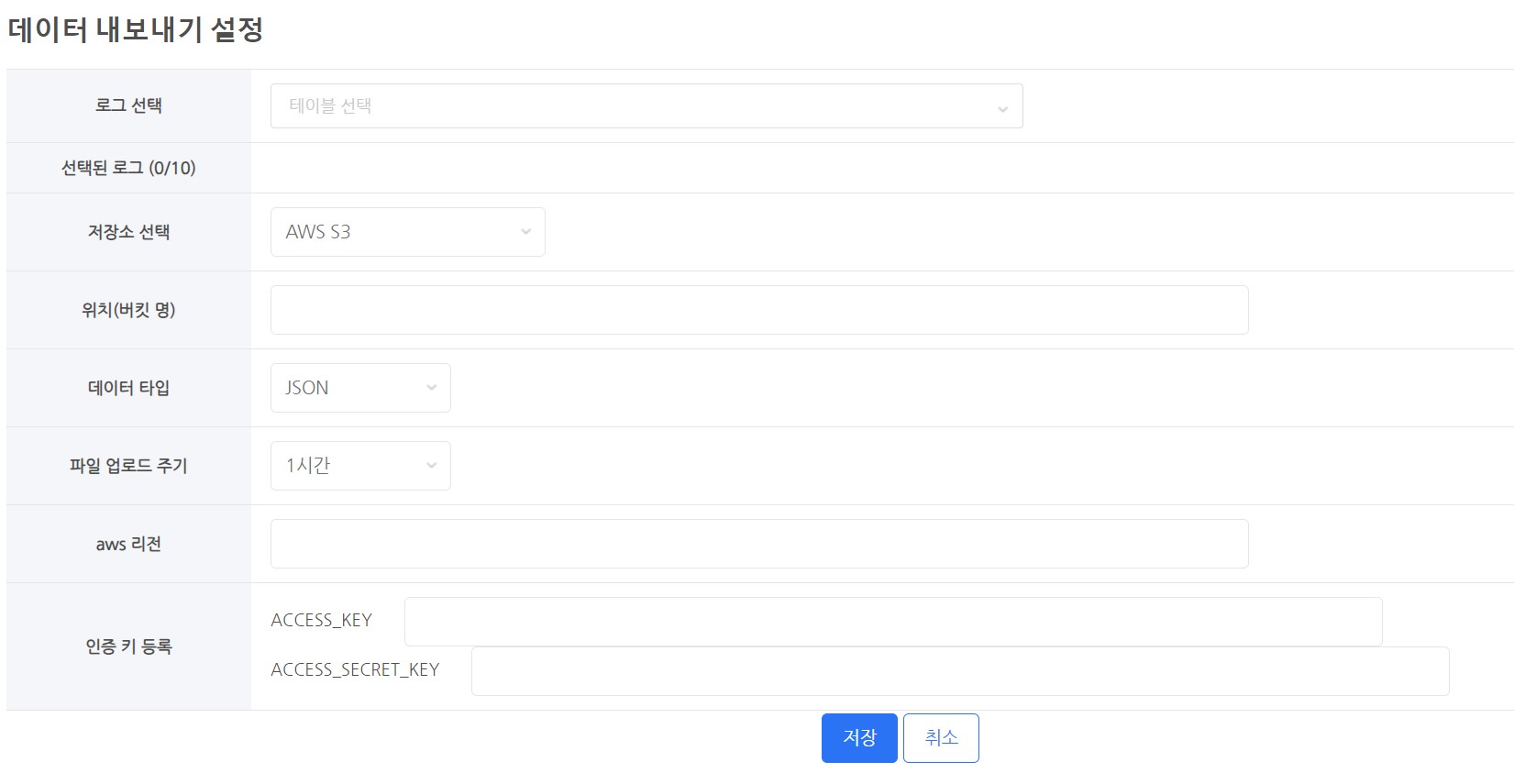
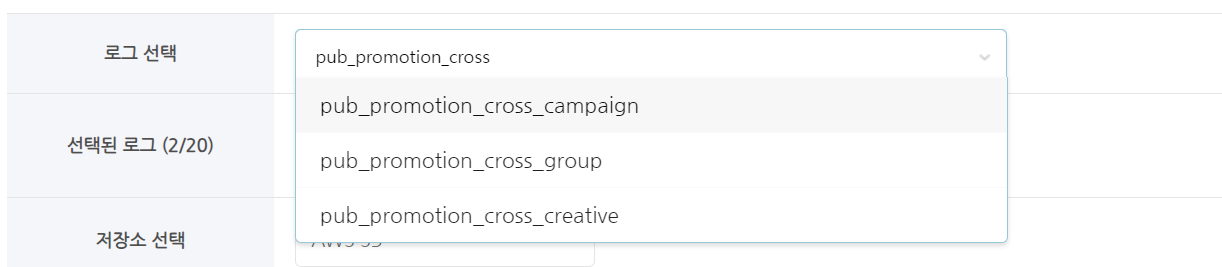
로그 선택¶
-
추출할 테이블(로그)를 선택 합니다.
-
테이블명 일부를 기재하여 검색 및 선택이 가능합니다.
-
테이블은 최대 10개까지 선택 가능합니다.

-
저장소 선택¶
- 데이터를 저장하기 위한 저장소로 클라우드 스토리지를 사용해야 합니다.
- 지원 클라우드
- AWS S3
- GCP google Cloud Storage
위치(버킷 명)¶
- 저장소의 버킷(bucket)명을 기재합니다.
- 예시)
- AWS S3 버킷명이 s3://s3_bucket_name 인 경우
- s3_bucket_name 만 기재
- Google Cloud Storage 버킷명이 gs://google_bucket_name 인 경우
- google_bucket_name 만 기재
- AWS S3 버킷명이 s3://s3_bucket_name 인 경우
데이터 타입¶
- 데이터 타입은 두가지 타입을 제공합니다.
- 제공하는 데이터 타입
- CSV
- JSON
- 모든 파일은 UTF-8로 인코딩 됩니다.
파일 업로드 주기¶
- 매시간 한시간 범위 데이터를 추출하여 업로드가 진행 됩니다.
- 시간은 bigqueryRegistTimestamp 컬럼값을 기준으로 추출 됩니다. (UTC 기준)
- 예시) 15시에 데이터 추출 및 업로드 시작(UTC기준)
- bigqueryRegistTimestamp 컬럼에서 05:00:00 ~ 05:59:59 의 데이터가 추출 됩니다.
- 파일 수와 업로드 용량에 따라 완료 시간은 달라질 수 있습니다.
- 예시) 15시에 데이터 추출 및 업로드 시작(UTC기준)
인증 키 등록¶
- 클라우드 스토리지에 데이터 업로드를 위해선 권한이 필요합니다.
- 데이터 저장 권한을 가진 인증키 또는 인증키 파일 등록을 해주셔야 합니다.
-
클라우드 서비스에 따라 인증 키 등록 방식이 다릅니다.

- S3 - ACCESS_KEY, ACCESS_SECRET_KEY 값 등록

- GCS - 인증키 파일 등록
클라우드 스토리지¶
GCP - Google Cloud Storage¶
- 구글 클라우드에 데이터 내보내기을 하기 위해서는 다음과 같은 설정이 필요합니다.
-
구글 클라우드 콘솔 페이지에서 Cloud Storage로 이동합니다.

-
데이터 내보내기를 전용으로 사용할 버킷(bucket) 을 생성 합니다.
- 버킷(bucket) 이름은 한번 설정하면 변경할 수 없으며 필요한 경우 기존 버킷을 삭제하고 새로 생성해야 합니다.
- 데이터 내보내기 전용 버킷으로 생성 하는 것을 권장
-
데이터 내보내기에 제공할 서비스키를 생성하여 버킷에 쓰기 권한을 부여 해야 합니다.
- 콘솔 페이지에서 IAM 및 관리자 → 서비스 계정 메뉴로 이동합니다.
-
서비스 계정 만들기를 클릭해서 새로운 계정을 생성합니다.
-
계정에 사용하는 ID는 원하는 이름으로 생성하시면 됩니다.
- 예) hive_data_transfer_account@projectId.iam.gserviceaccount.com 2. 계정 생성 후 키 탭으로 이동하여 서비스용 키를 생성합니다.

- 키 추가 → 새 키 만들기로 JSON 형태의 키 파일을 생성 합니다.
- 생성한 키 파일은 다운로드 받은 후 잘 보관 합니다.
-
-
이후 다시 Cloud Storage로 이동하여 생성한 버킷(bucket)에서 권한 탭으로 이동합니다.

- 권한 탭에서 엑세스 권한 부여 → 주 구성원 추가에 새로 생성한 서비스 계정 ID를 입력합니다.
- 역활 지정에서 Cloud Storage → 저장소 개체 생성자, 저장소 개체 뷰어 두가지 권한을 추가 한 후 확인을 클릭합니다.
-
모든 설정이 완료 된 후 하이브 애널리틱스의 데이터 내보내기 설정 페이지에 서비스용 키 파일을 등록 합니다.
AWS - S3¶
- AWS에 데이터 내보내기을 하기 위해서는 다음과 같은 설정이 필요합니다.
-
AWS의 콘솔 페이지에서 스토리지 → S3 로 이동합니다.

-
데이터 내보내기 전용 버킷(bucket)을 생성합니다.
- 버킷(bucket) 이름은 한번 설정하면 변경할 수 없으며 필요한 경우 기존 버킷을 삭제하고 새로 생성해야 합니다.
- 데이터 내보내기 전용 버킷으로만 사용을 권장 합니다.
-
데이터 내보내기을 위한 계정을 생성해야 합니다.
- 이 사용자는 데이터 내보내기을 위한 전용 계정으로만 사용되어야 합니다. IAM user를 새로 생성합니다.
-
생성한 계정의 액세스 키를 생성합니다. 관련 정보는 IAM 사용자의 액세스 키 관리 - 액세스 키 생성에서 확인 가능합니다.
- 액세스 키는 안전한 곳에 보관합니다
-
생성한 계정에 대해 inline policy를 추가 합니다.
- 사용자 그룹의 인라인 정책을 포함하려면(콘솔) - 항목을 참고하여 정책을 생성 합니다.
-
JSON 탭을 선택하여 policy를 만들고, 다음의 JSON 코드를 붙여 넣기 합니다.
1.YOUR-BUCKET-NAME-HERE 항목은 생성한 버킷명을 기재 합니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:GetBucketLocation", "s3:ListBucket"],
"Resource": ["arn:aws:s3:::YOUR-BUCKET-NAME-HERE"]
},
{
"Effect": "Allow",
"Action": ["s3:PutObject"],
"Resource": ["arn:aws:s3:::YOUR-BUCKET-NAME-HERE/*"]
}
]
}
6. 모든 작업을 완료 한 후 보관한 액세스 키를 하이브 콘솔 데이터 내보내기 설정에 추가 합니다.
파일 저장 형식¶
데이터 저장 디렉토리 구조¶
- 일반적인 파일 형식
- withhive/data_export/빌드타입/YYYY/MM/DD/테이블명/테이블명_YYYY_MM_DD_UUID.파일확장자
- 빌드 타입 : sandbox와 live 두 가지 값을 가집니다. sandbox에서 설정 시 sandbox로 저장 됩니다.
- YYYY/MM/DD : 데이터가 추출 되는 기준 년/월/일 입니다. (UTC 기준)
- UUID : 파일명 중복으로 인한 덮어 씌우기 방지를 위한 랜덤 값입니다.
-
파일 확장자 : 선택한 파일 타입에 따라 달라집니다.
- withhive/data_export/빌드타입/YYYY/MM/DD/테이블명/테이블명_YYYY_MM_DD_UUID.파일확장자
| 파일 타입 | 압축 여부 | 최종 파일명 |
|---|---|---|
| json | V | withhive/data_export/빌드타입/YYYY/MM/DD/테이블명/테이블명_YYYY_MM_DD_UUID.json.gzip |
| csv | V | withhive/data_export/빌드타입/YYYY/MM/DD/테이블명/테이블명_YYYY_MM_DD_UUID.csv.gzip |
파일 확장자¶
- csv.gzip
- 필드를 쉼표( , ) 로 구분한 데이터로 구성된 파일 입니다.
- 파일 압축 시 암호화 설정은 불가능 합니다(미지원)
- json.gzip
- Javascript 객체 문법으로 구조화된 데이터 문자로 구성된 파일 입니다.
- 라인 단위로 구분 되어있습니다.
- json 파일을 gzip으로 압축한 파일 입니다.
- 파일 압축 시 암호화 설정은 불가능 합니다(미지원)
전송 제한 안내¶
- 최대 테이블 수 제한
- 선택 가능한 최대 테이블 수 : 10개
- 테이블당 추출 데이터 총 용량 제한
- 데이터 추출 시 500Mbytes를 초과 : 전송 제외
- 실제 전송 되는 데이터는 약 15%정도로 압축 된 파일입니다.
- 데이터 추출 시 500Mbytes를 초과 : 전송 제외