การส่งออกข้อมูล
การแนะนำการส่งออกข้อมูล¶
นี่คือบริการที่ดึงข้อมูลบันทึกจาก Hive Analytics ทุกชั่วโมงและโอนย้ายไปยังพื้นที่จัดเก็บบนคลาวด์
ข้อมูลที่ผลิตโดยการส่งออกข้อมูลสามารถนำไปใช้ในการวิเคราะห์ได้ตามต้องการ ไม่ว่าจะโดยการสร้างฐานข้อมูลโดยตรงเป็นข้อมูลดิบหรือโดยการประมวลผลให้เป็นรูปแบบที่จำเป็น
Hive Analytics มีบริการแปลงไฟล์และการถ่ายโอนข้อมูล อย่างไรก็ตาม การจัดเก็บข้อมูลในคลาวด์ต้องการการลงทะเบียนกับผู้ให้บริการคลาวด์ที่คุณกำลังใช้
หลักการส่งออกข้อมูล¶
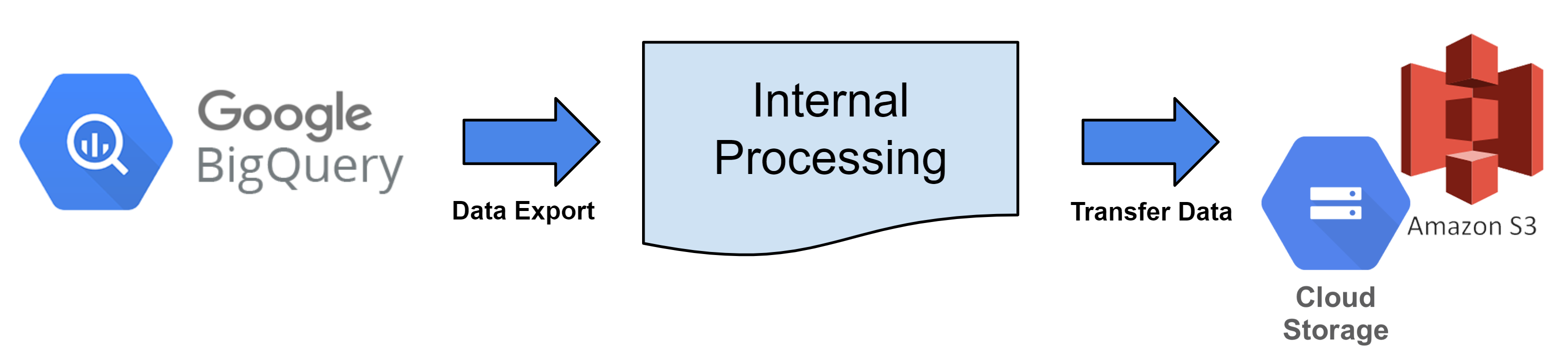
ทุกชั่วโมง ตาราง BigQuery จะถูกแปลงเป็นไฟล์ตามรอบการส่งออกข้อมูลและอัปโหลดไปยังพื้นที่จัดเก็บคลาวด์ที่ลงทะเบียน
สิทธิ์ในการส่งออกข้อมูล¶
- ในการใช้ฟังก์ชันการส่งออกข้อมูล คุณต้องเข้าถึงเกมทั้งหมดหรือมีบัญชี Hive
- เนื่องจากข้อมูลถูกส่งมอบโดยตาราง (log) การส่งข้อมูลแยกตามเกมจึงเป็นไปไม่ได้
เกณฑ์ข้อมูลการส่งออกข้อมูล¶
- ค้นหาข้อมูลในตารางที่เลือกและอัปโหลดไฟล์ไปยังพื้นที่เก็บข้อมูลบนคลาวด์。
- ข้อมูลจะถูกดึงออกโดยใช้รอบการส่งข้อมูลตามชั่วโมงตาม UTC。 ตัวอย่าง) ดึงข้อมูลวันที่ 1 ก.ย. 2023 เวลา 00:00:00 - 00:59:59 (UTC) ในวันที่ 1 ก.ย. 2023 เวลา 1:00 (UTC)。
- มาตรฐานการแบ่งพาร์ติชันสำหรับคอลัมน์วันที่และเวลาจะถูกตั้งค่าเป็นวันที่ดูลบหนึ่งวัน。 ตัวอย่าง) 30 ส.ค. 2023 เวลา 00:00:00 เมื่อดึงข้อมูลจากวันที่ 1 ก.ย. 2023 เวลา 00:00:00 ถึง 00:59:59 (UTC)。
- หากค่าของวันที่และเวลาน้อยกว่าช่วงเวลาที่สอบถามลบหนึ่งวัน จะถูกยกเว้นจากข้อมูลที่ส่งออก。
- มาตรฐานการแบ่งพาร์ติชันสำหรับคอลัมน์วันที่และเวลาจะถูกตั้งค่าเป็นวันที่ดูลบหนึ่งวัน。 ตัวอย่าง) 30 ส.ค. 2023 เวลา 00:00:00 เมื่อดึงข้อมูลจากวันที่ 1 ก.ย. 2023 เวลา 00:00:00 ถึง 00:59:59 (UTC)。
- ข้อมูลจะถูกค้นหาตามเวลาที่ป้อนเข้าสู่ Big Query。
- เกณฑ์คอลัมน์ bigqueryRegistTimestamp
- ตัวอย่างคำสั่งดึงข้อมูล
SELECT *
FROM bigquery_table
WHERE bigqueryRegistTimestamp BETWEEN '2023-09-01 00:00:00' and '2023-09-01 00:59:59'
and datetime >= '2023-08-31 00:00:00'
การตั้งค่าการส่งออกข้อมูล¶
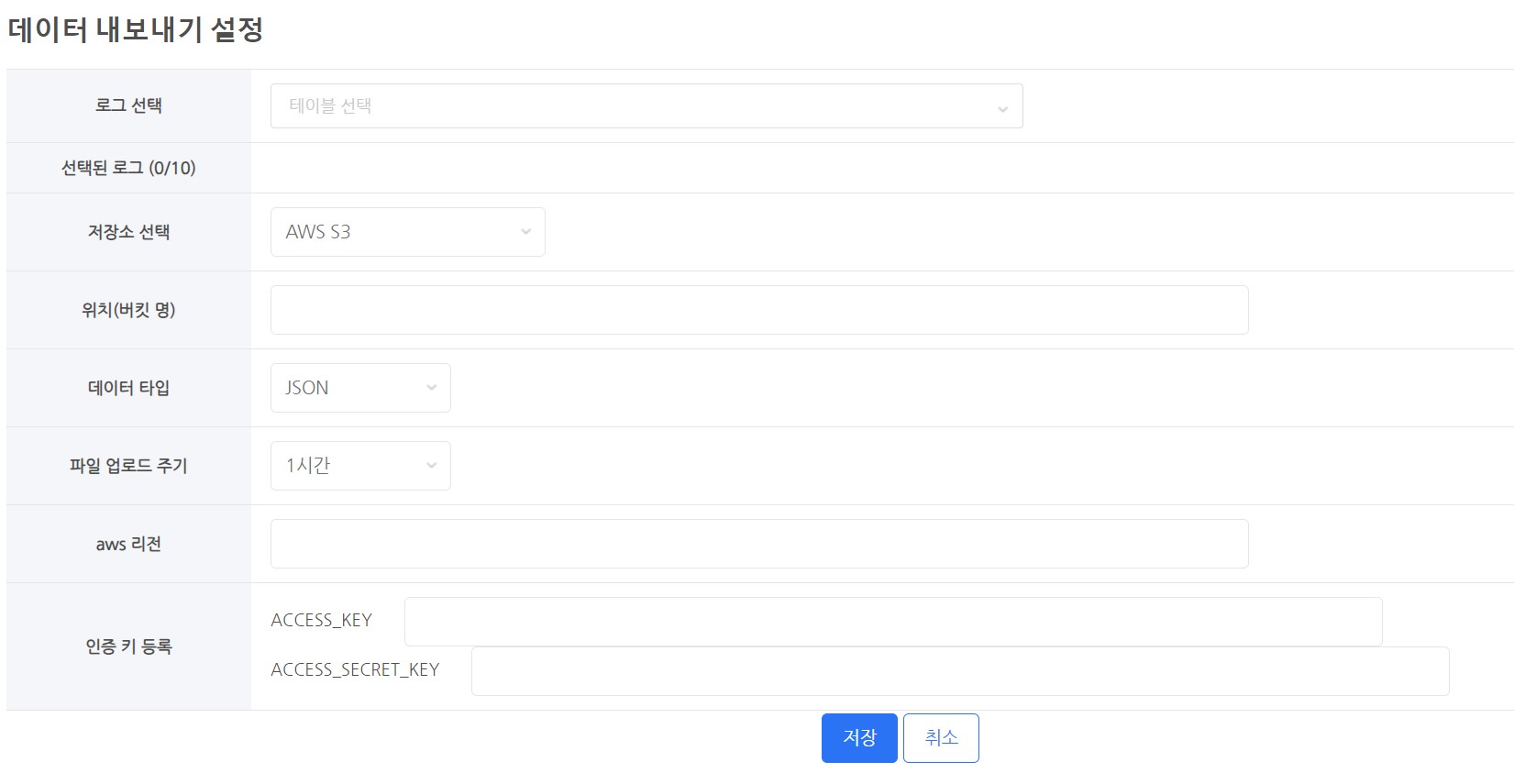
เลือกบันทึก¶
- เลือกตาราง (ล็อก) เพื่อดึงข้อมูล
- คุณสามารถค้นหาและเลือกโดยการป้อนส่วนหนึ่งของชื่อ ตาราง
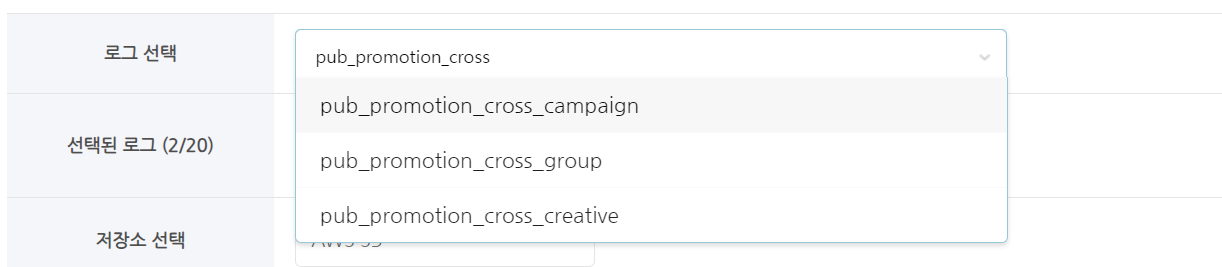
- คุณสามารถเลือกได้สูงสุดถึงสิบตาราง

- คุณสามารถค้นหาและเลือกโดยการป้อนส่วนหนึ่งของชื่อ ตาราง
เลือกที่จัดเก็บ¶
- คุณต้องใช้การจัดเก็บข้อมูลบนคลาวด์เพื่อเก็บข้อมูลของคุณ
- คลาวด์ที่รองรับ
- AWS S3
- GCP Google Cloud Storage
สถานที่ (ชื่อถัง)¶
- กรุณาใส่ชื่อบัคเก็ตของพื้นที่จัดเก็บข้อมูล
- เช่น)
- ถ้าชื่อบัคเก็ต AWS S3 คือ s3://s3_bucket_name,
- ให้ใส่เพียง 's3_bucket_name' เท่านั้น
- ถ้าชื่อบัคเก็ต Google Cloud Storage คือ gs://google_bucket_name,
- ให้ใส่เพียง 'google_bucket_name' เท่านั้น
- ถ้าชื่อบัคเก็ต AWS S3 คือ s3://s3_bucket_name,
ประเภทข้อมูล¶
- มีประเภทข้อมูลสองประเภท
- ประเภทข้อมูลที่ให้มา
- CSV
- JSON
- ไฟล์ทั้งหมดถูกเข้ารหัสใน UTF-8
วงจรการอัปโหลดไฟล์¶
- ข้อมูลจากช่วงเวลาทุกชั่วโมงจะถูกดึงและอัปโหลดทุกชั่วโมง
- เวลาจะอิงจากค่าของคอลัมน์ bigqueryRegistTimestamp สำหรับการดึงข้อมูล (ตาม UTC)
- เช่น) เริ่มดึงและอัปโหลดข้อมูลที่ 15:00 (UTC)
- คอลัมน์ bigqueryRegistTimestamp มีข้อมูลตั้งแต่ 05:00:00 ถึง 05:59:59
- เวลาที่ใช้ในการทำงานอาจแตกต่างกันไปตามจำนวนไฟล์และขนาดของการอัปโหลด
- เช่น) เริ่มดึงและอัปโหลดข้อมูลที่ 15:00 (UTC)
ลงทะเบียนคีย์การตรวจสอบสิทธิ์¶
- จำเป็นต้องมีการอนุญาตในการอัปโหลดข้อมูลไปยังพื้นที่จัดเก็บข้อมูลบนคลาวด์
- คุณต้องลงทะเบียนคีย์การตรวจสอบสิทธิ์หรือไฟล์คีย์การตรวจสอบสิทธิ์ที่มีสิทธิ์ในการจัดเก็บข้อมูล
- เทคนิคการลงทะเบียนคีย์การตรวจสอบสิทธิ์จะแตกต่างกันไปตามบริการคลาวด์

- S3 - ลงทะเบียนค่าการตรวจสอบสิทธิ์ ACCESS_KEY, ACCESS_SECRET_KEY

- GCS - ลงทะเบียนไฟล์คีย์การตรวจสอบสิทธิ์
การจัดเก็บข้อมูลบนคลาวด์¶
GCP - Google cloud storage¶
- ในการส่งออกข้อมูลไปยัง Google Cloud จะต้องมีการกำหนดค่าดังต่อไปนี้
-
- ไปที่หน้า Google Cloud Console และเลือก Cloud Storage.

- สร้างบัคเก็ตเฉพาะสำหรับการส่งออกข้อมูล.
- เมื่อกำหนดแล้ว ชื่อบัคเก็ตไม่สามารถเปลี่ยนแปลงได้ หากจำเป็นให้ลบบัคเก็ตเก่าและสร้างบัคเก็ตใหม่
- แนะนำให้สร้างบัคเก็ตที่ใช้สำหรับการส่งออกข้อมูลโดยเฉพาะ
- เพื่อเปิดใช้งานการส่งออกข้อมูล ให้สร้างคีย์บริการและมอบสิทธิ์การเขียนให้กับบัคเก็ต
- เลือก IAM & Admin → บัญชีบริการจากหน้า Console
- ในการตั้งค่าบัญชีใหม่ ให้คลิก สร้างบัญชีบริการ.
- คุณสามารถให้บัญชีของคุณมี ID ที่ตรงกับชื่อที่ต้องการ
- เช่น) hive_data_transfer_account@projectId.iam.gserviceaccount.com
- หลังจากสร้างบัญชีแล้ว ให้ไปที่แท็บ Keys และสร้างคีย์สำหรับบริการ

- สร้างไฟล์คีย์ในรูปแบบ JSON จาก Add Key → Create New Key.
- หลังจากดาวน์โหลดไฟล์คีย์ที่สร้างขึ้น ให้เก็บรักษาอย่างปลอดภัย
- คุณสามารถให้บัญชีของคุณมี ID ที่ตรงกับชื่อที่ต้องการ
- ถัดไป กลับไปที่ Cloud Storage และไปที่แท็บ Permissions ใน บัคเก็ต ที่คุณสร้าง

- ในแท็บ Permissions ให้ป้อน ID ของบัญชีบริการที่สร้างขึ้นใหม่ใน Grant Access → Add Main Member.
- ในการมอบบทบาท ให้ตรวจสอบสิทธิ์สองรายการ: Cloud Storage → ผู้สร้างวัตถุจัดเก็บ และ ผู้ดูวัตถุจัดเก็บ จากนั้นคลิก OK.
- เมื่อคุณตั้งค่าทั้งหมดเสร็จแล้ว ให้ไปที่หน้าการตั้งค่าการส่งออกข้อมูลของ Hive Analytics และลงทะเบียนไฟล์คีย์ของบริการ
- ไปที่หน้า Google Cloud Console และเลือก Cloud Storage.
AWS - S3¶
- ในการส่งออกข้อมูลไปยัง AWS จำเป็นต้องมีการกำหนดค่าดังต่อไปนี้
-
- ไปที่ Storage → S3 ใน AWS console

- สร้าง bucket สำหรับการส่งออกข้อมูล
- เมื่อกำหนดชื่อแล้ว ชื่อ bucket จะไม่สามารถแก้ไขได้ หากจำเป็นให้ลบ bucket เก่าและสร้างใหม่
- แนะนำให้สร้าง bucket ที่ใช้เฉพาะสำหรับการส่งออกข้อมูล
- สร้าง bucket สำหรับการส่งออกข้อมูล
- ผู้ใช้รายนี้ควรใช้เป็นบัญชีแยกต่างหากสำหรับการส่งออกข้อมูล สร้าง IAM user ใหม่
- สร้าง access key สำหรับบัญชีที่คุณได้สร้าง ข้อมูลที่เกี่ยวข้องสามารถดูได้ที่ IAM user's Manage Access Key - Create Access Key.
- เก็บ access keys ของคุณไว้ในสถานที่ที่ปลอดภัย
- เพิ่ม inline policy สำหรับบัญชีที่สร้างขึ้น
- ในการรวม inline policy สำหรับกลุ่มผู้ใช้ (console) ให้ทำตามขั้นตอนในหัวข้อการสร้างนโยบาย
-
ในการสร้างนโยบาย ให้เลือกแท็บ JSON และวางโค้ด JSON ที่แสดงด้านล่าง
- ฟิลด์ YOUR-BUCKET-NAME-HERE รวมถึงชื่อของบัคเก็ตที่คุณสร้างขึ้น
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": ["s3:GetBucketLocation", "s3:ListBucket"], "Resource": ["arn:aws:s3:::YOUR-BUCKET-NAME-HERE"] }, { "Effect": "Allow", "Action": ["s3:PutObject"], "Resource": ["arn:aws:s3:::YOUR-BUCKET-NAME-HERE/*"] } ] }
- ฟิลด์ YOUR-BUCKET-NAME-HERE รวมถึงชื่อของบัคเก็ตที่คุณสร้างขึ้น
- เมื่อคุณทำทุกอย่างเสร็จแล้ว ให้เพิ่มคีย์การเข้าถึงที่เก็บไว้ไปยังตัวเลือกการส่งออกข้อมูลของ Hive console.
- ไปที่ Storage → S3 ใน AWS console
รูปแบบการจัดเก็บไฟล์¶
โครงสร้างไดเรกทอรีการจัดเก็บข้อมูล¶
- รูปแบบไฟล์ทั่วไป
- withhive/data_export/Build_Type/YYYY/MM/DD/TableName/TableName_YYYY_MM_DD_UUID.fileExtension
- ประเภทการสร้าง: มีค่าที่เป็นไปได้สองค่า: sandbox และ live เมื่อตั้งค่าเป็น sandbox จะบันทึกเป็น sandbox.
- YYYY/MM/DD : นี่คือปี/เดือน/วันที่มาตรฐานที่ข้อมูลถูกดึงออกมา (ตาม UTC)
- UUID : นี่คือค่าที่สุ่มซึ่งป้องกันการเขียนทับเนื่องจากชื่อไฟล์ซ้ำกัน.
-
นามสกุลไฟล์: แตกต่างกันไปตามประเภทไฟล์ที่เลือก.
- withhive/data_export/Build_Type/YYYY/MM/DD/TableName/TableName_YYYY_MM_DD_UUID.fileExtension
| ประเภทไฟล์ | สถานะการบีบอัด | ชื่อไฟล์สุดท้าย |
|---|---|---|
| json | V | withhive/data_export/BuildType/YYYY/MM/DD/TableName/TableName_YYYY_MM_DD_UUID.json.gzip |
| csv | V | withhive/data_export/BuildType/YYYY/MM/DD/TableName/TableName_YYYY_MM_DD_UUID.csv.gzip |
นามสกุลไฟล์¶
- csv.gzip
- นี่คือไฟล์ที่มีข้อมูลที่มีฟิลด์แยกด้วยเครื่องหมายจุลภาค.
- การตั้งค่าการเข้ารหัสไม่สามารถใช้ได้เมื่อบีบอัดไฟล์. (ไม่รองรับ)
- json.gzip
- นี่คือไฟล์ที่มีตัวอักษรข้อมูลที่จัดระเบียบในไวยากรณ์วัตถุของ Javascript.
- มันถูกแยกเป็นบรรทัด.
- นี่คือไฟล์ json ที่ถูกบีบอัดด้วย gzip.
- การตั้งค่าการเข้ารหัสไม่สามารถใช้ได้เมื่อบีบอัดไฟล์. (ไม่รองรับ)
การแจ้งเตือนขีดจำกัดการส่ง¶
- ขีดจำกัดจำนวนโต๊ะสูงสุด
- โต๊ะที่เลือกได้สูงสุด: 10
- ขีดจำกัดความจุข้อมูลที่ดึงข้อมูลตามโต๊ะ
- เกิน 500Mbytes เมื่อดึงข้อมูล: ไม่รวมในการส่งข้อมูล
- ข้อมูลที่ถูกส่งจริงเป็นไฟล์ที่บีบอัดประมาณ 15%.
- เกิน 500Mbytes เมื่อดึงข้อมูล: ไม่รวมในการส่งข้อมูล