数据导出
数据导出介绍¶
这是一个每小时从Hive Analytics提取日志数据并将其传输到云存储的服务。
数据导出生成的数据可以根据需要用于分析,既可以直接作为原始数据建立数据库,也可以将其处理成所需格式。
Hive Analytics 提供文件转换和数据传输,但云存储需要与您正在使用的云服务提供商注册。
数据导出逻辑¶
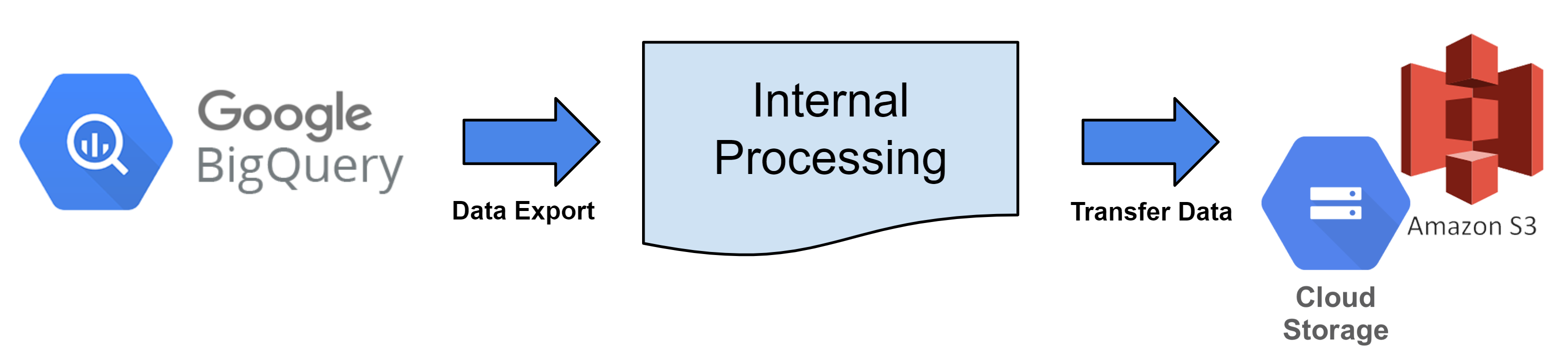
每小时,BigQuery 表会根据数据导出周期转换为文件并上传到注册的云存储。
数据导出服务权限¶
- 要使用数据导出功能,您必须访问所有游戏或拥有一个Hive账户。
- 因为数据是通过表(日志)传递的,按游戏分割传输是不可能的。
数据导出数据标准¶
- 搜索所选表的数据并将文件上传到云存储。
- 数据是基于UTC的每小时传输周期提取的。 例如)提取2023年9月1日00:00:00 - 00:59:59(UTC)在2023年9月1日1:00(UTC)的数据。
- 日期时间列的分区标准设置为查看日期减去一天。 例如)在提取2023年9月1日00:00:00到00:59:59(UTC)时为2023年8月30日00:00:00。
- 如果日期时间的值小于查询时间减去一天,它将被排除在导出数据之外。
- 日期时间列的分区标准设置为查看日期减去一天。 例如)在提取2023年9月1日00:00:00到00:59:59(UTC)时为2023年8月30日00:00:00。
- 数据是根据输入到Big Query的时间进行搜索的。
- bigqueryRegistTimestamp列标准
- 数据提取示例查询
SELECT *
FROM bigquery_table
WHERE bigqueryRegistTimestamp BETWEEN '2023-09-01 00:00:00' and '2023-09-01 00:59:59'
and datetime >= '2023-08-31 00:00:00'
数据导出设置¶
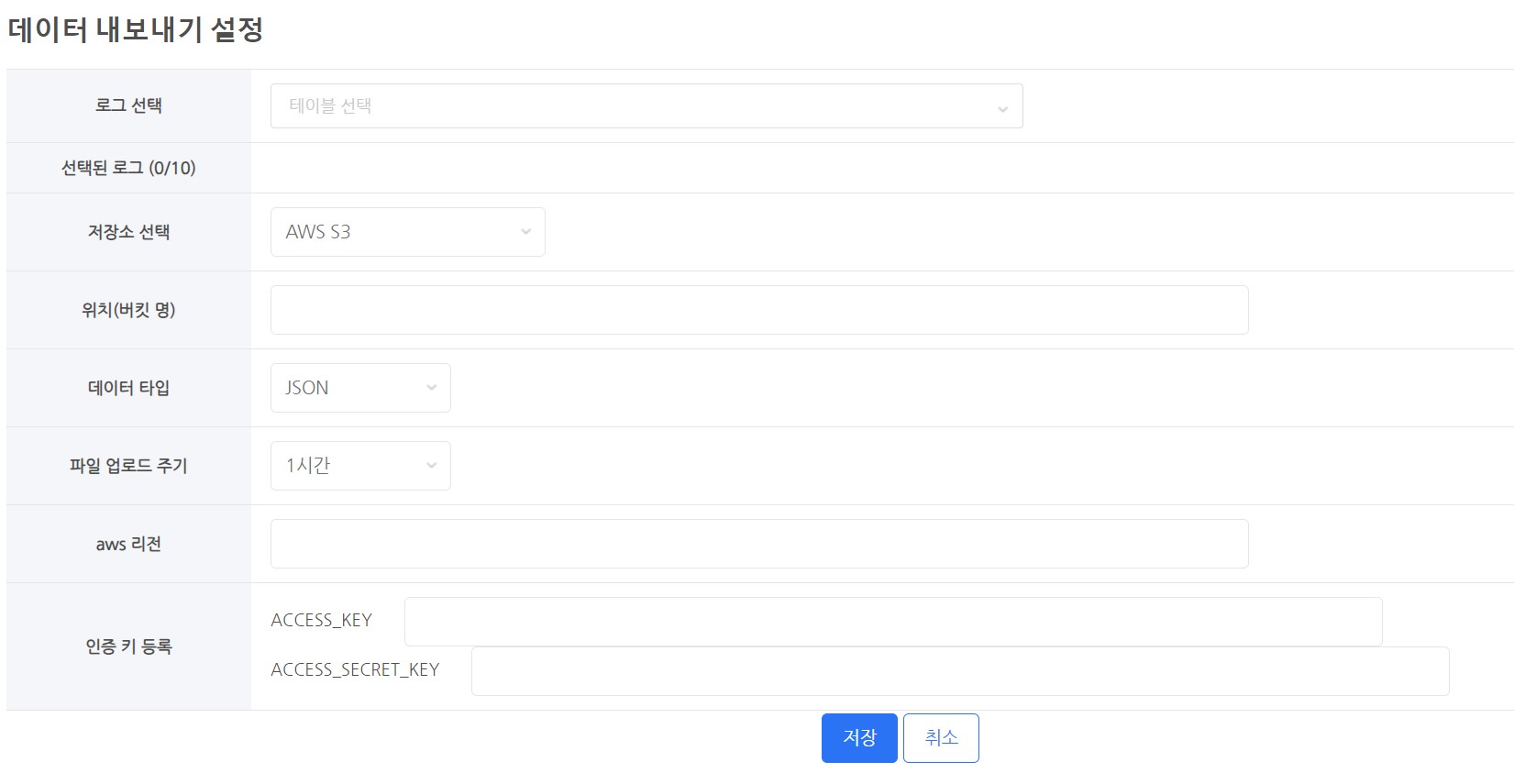
选择日志¶
- 选择一个表(日志)进行提取。
- 您可以通过输入表名的一部分来搜索和选择。
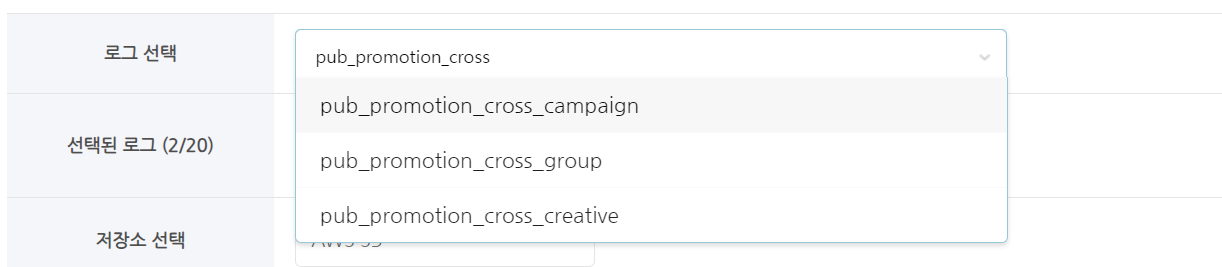
- 您最多可以选择十个表。

- 您可以通过输入表名的一部分来搜索和选择。
选择存储¶
- 您需要使用云存储来存储您的数据。
- 支持的云
- AWS S3
- GCP 谷歌云存储
位置(桶名称)¶
- 输入存储的桶名称。
- 例如:
- 如果 AWS S3 桶名称是 s3://s3_bucket_name,
- 仅输入 's3_bucket_name'
- 如果 Google Cloud Storage 桶名称是 gs://google_bucket_name,
- 仅输入 'google_bucket_name'
- 如果 AWS S3 桶名称是 s3://s3_bucket_name,
数据类型¶
- 有两种数据类型。
- 提供的数据类型
- CSV
- JSON
- 所有文件均以 UTF-8 编码。
文件上传周期¶
- 每小时提取和上传一个小时范围内的数据。
- 提取的时间基于bigqueryRegistTimestamp列的值。(基于UTC)
- 例如)在15:00(UTC)开始提取和上传数据。
- bigqueryRegistTimestamp列的数据范围为05:00:00到05:59:59。
- 完成时间可能会根据文件数量和上传大小而有所不同。
- 例如)在15:00(UTC)开始提取和上传数据。
注册认证密钥¶
- 上传数据到云存储需要权限。
- 您必须注册一个具有数据存储权限的认证密钥或认证密钥文件。
- 认证密钥注册技术因云服务而异。

- S3 - 注册认证值 ACCESS_KEY, ACCESS_SECRET_KEY

- GCS - 注册认证密钥文件
云存储¶
GCP - 谷歌云存储¶
- 要将数据导出到 Google Cloud,需要以下配置。
-
- 访问 Google Cloud 控制台页面并选择 Cloud Storage。

- 创建一个存储桶专门用于数据导出。
- 一旦设置,存储桶名称无法修改。如果需要,请删除旧存储桶并创建一个新存储桶。
- 建议创建一个专用于数据导出的存储桶。
- 要启用数据导出,请创建一个服务密钥并授予存储桶写入权限。
- 从控制台页面选择 IAM & 管理 → 服务帐户。
- 要设置新帐户,请点击 创建服务帐户。
- 您可以为您的帐户指定一个与所需名称匹配的 ID。
- 例如) hive_data_transfer_account@projectId.iam.gserviceaccount.com
- 创建帐户后,导航到密钥选项卡并为服务生成密钥。

- 从添加密钥 → 创建新密钥中创建 JSON 格式的密钥文件。
- 下载创建的密钥文件后,请妥善保管。
- 您可以为您的帐户指定一个与所需名称匹配的 ID。
- 接下来,返回到 Cloud Storage,并转到您创建的 存储桶 的权限选项卡。

- 在权限选项卡中,在授予访问权限 → 添加主要成员中输入新创建的服务帐户 ID。
- 在角色分配中,检查两个权限:Cloud Storage → 存储对象创建者 和 存储对象查看者,然后点击确定。
- 完成所有设置后,前往 Hive Analytics 的数据导出设置页面并注册服务的密钥文件。
- 访问 Google Cloud 控制台页面并选择 Cloud Storage。
AWS - S3¶
- 要将数据导出到AWS,以下配置是必要的。
-
- 在AWS控制台中转到存储 → S3。

- 为数据导出创建一个存储桶。
- 设置后,存储桶名称无法修改。如有必要,请删除旧存储桶并创建一个新存储桶。
- 建议创建一个专用于数据导出的存储桶。
- 为数据导出创建一个存储桶。
- 此用户应仅用作数据导出的独立帐户。创建一个新的IAM用户。
- 为您创建的帐户创建一个访问密钥。相关信息可以在IAM用户的管理访问密钥 - 创建访问密钥中找到。
- 将您的访问密钥保存在安全的位置。
- 为创建的帐户添加内联策略。
- 要为用户组(控制台)包含内联策略,请按照策略创建主题中的步骤进行操作。
-
要建立策略,请选择JSON选项卡并粘贴下面显示的JSON代码。
- YOUR-BUCKET-NAME-HERE字段包括您建立的存储桶的名称。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": ["s3:GetBucketLocation", "s3:ListBucket"], "Resource": ["arn:aws:s3:::YOUR-BUCKET-NAME-HERE"] }, { "Effect": "Allow", "Action": ["s3:PutObject"], "Resource": ["arn:aws:s3:::YOUR-BUCKET-NAME-HERE/*"] } ] }
- YOUR-BUCKET-NAME-HERE字段包括您建立的存储桶的名称。
- 完成所有操作后,将归档的访问密钥添加到Hive控制台数据导出选项中。
- 在AWS控制台中转到存储 → S3。
文件存储格式¶
数据存储目录结构¶
- 常见文件格式
- withhive/data_export/Build_Type/YYYY/MM/DD/TableName/TableName_YYYY_MM_DD_UUID.fileExtension
- 构建类型:有两个可能的值:sandbox和live。当设置为sandbox时,保存为sandbox。
- YYYY/MM/DD:这是提取数据的标准年/月/日。(基于UTC)
- UUID:这是一个随机值,防止因重复文件名而覆盖。
-
文件扩展名:根据所选文件类型而有所不同。
- withhive/data_export/Build_Type/YYYY/MM/DD/TableName/TableName_YYYY_MM_DD_UUID.fileExtension
| 文件类型 | 压缩状态 | 最终文件名 |
|---|---|---|
| json | V | withhive/data_export/BuildType/YYYY/MM/DD/TableName/TableName_YYYY_MM_DD_UUID.json.gzip |
| csv | V | withhive/data_export/BuildType/YYYY/MM/DD/TableName/TableName_YYYY_MM_DD_UUID.csv.gzip |
文件扩展名¶
- csv.gzip
- 这是一个包含用逗号分隔的字段的数据文件。
- 压缩文件时无法使用加密设置。(不支持)
- json.gzip
- 这是一个包含以Javascript对象语法组织的数据字符的文件。
- 它被分成多行。
- 这是一个用gzip压缩的json文件。
- 压缩文件时无法使用加密设置。(不支持)
传输限制通知¶
- 最大表数量限制
- 可选择的最大表数:10
- 按表提取数据总容量限制
- 提取数据时超过500Mbytes:不包括在传输中
- 实际传输的数据是约15%的压缩文件。
- 提取数据时超过500Mbytes:不包括在传输中